The Vibes Are Off
Table of contents
> wc -w ~ 3392
Reading time estimate ~ 17 minutes
Introduction
As a rule, I do not try to make it my business what tools other people are using to accomplish their goals. If you want to use Emacs, that's fine by me. IntelliJ's refactor tools a lifesaver? Have at it.
I am not, for example, opposed to the usage of tools like Github Copilot that have a strong element of human direction where users find them appropriate1.
However, there is a line where I think things do require comment.
If we are to be engineers, and we ought, then that comes with an obligation to ensure that our work in producing software is undertaken in a socially responsible way.
Consequently, if a tool cannot be used in a socially responsible way, we have an obligation to point that out.
It's my suspicion that the current style of "vibe coding" and the tools that back them, in the current social context, are difficult to use responsibly.
What is "vibe coding"?
I'm old and indifferent so the concept only crossed my desk at work in an unrelated discussion as an example of new AI novelties, so I'll presume the same of you.
There is a new trend of assistive coding tools and chat based IDEs that are essentially largely autonomous.
These tools, like Cursor.AI and especially Windsurf, aim to undertake a much larger share of the workload of an engineer in the micro, allowing the engineer to focus on the higher level direction of the task1.
These tools have multiple modes, some closer to human-in-the-loop with enhanced auto-complete like traditional Github Copilot flows, to fully chat driven intent based drafting2.
Like, watch this video from Windsurf to see what I mean in terms of the tooling:
"Vibe coding" is the practice of using the latter almost entirely, relying on the IDE to appropriately cash out your intent with the desired edits.
"Vibe coding" is meant to involve almost no direct inspection of the code. The tweet inventing the term builds that into the concept:
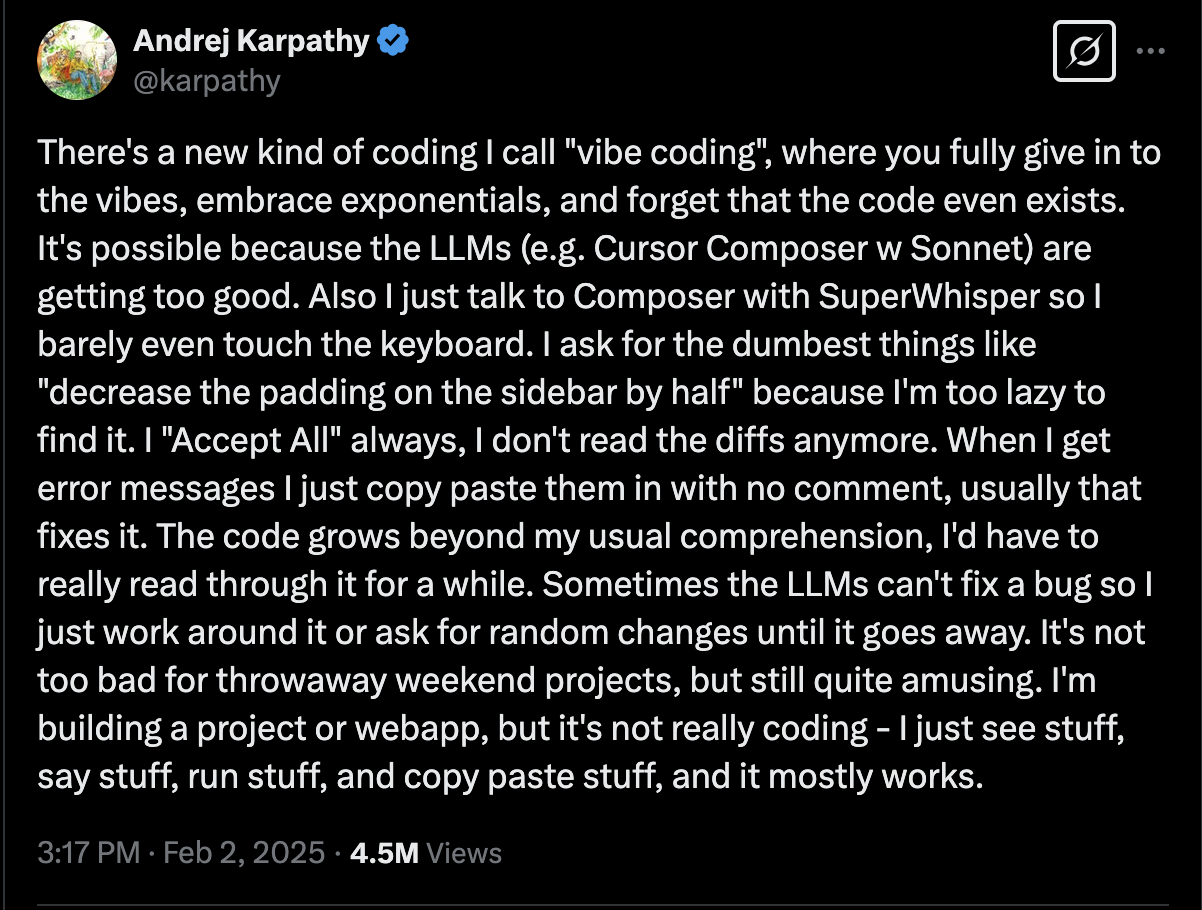
Now we should grant Karpathy that he scopes the practice solely to "throwaway weekend projects".
However, I want to point out a couple of features that already present themselves.
Firstly, the code "grows beyond my ability to comprehend". I think it's important to note that this consequence is immediate and acknowledged.
Secondly, the LLM sometimes "can't fix a bug", and so one is left just acting at random until the bug goes away. That might be worth thinking about.
Now, anyway, Andrej talks only about "throwaway weekend projects", but I wonder.
Is everyone taking it this way?
A Case Study
Short answer: No.
Recently, I came across two blog posts discussing a recent case where someone got a bit over their skis using this technique:
It all starts with this series of tweets, which I will call "Me Sowing":
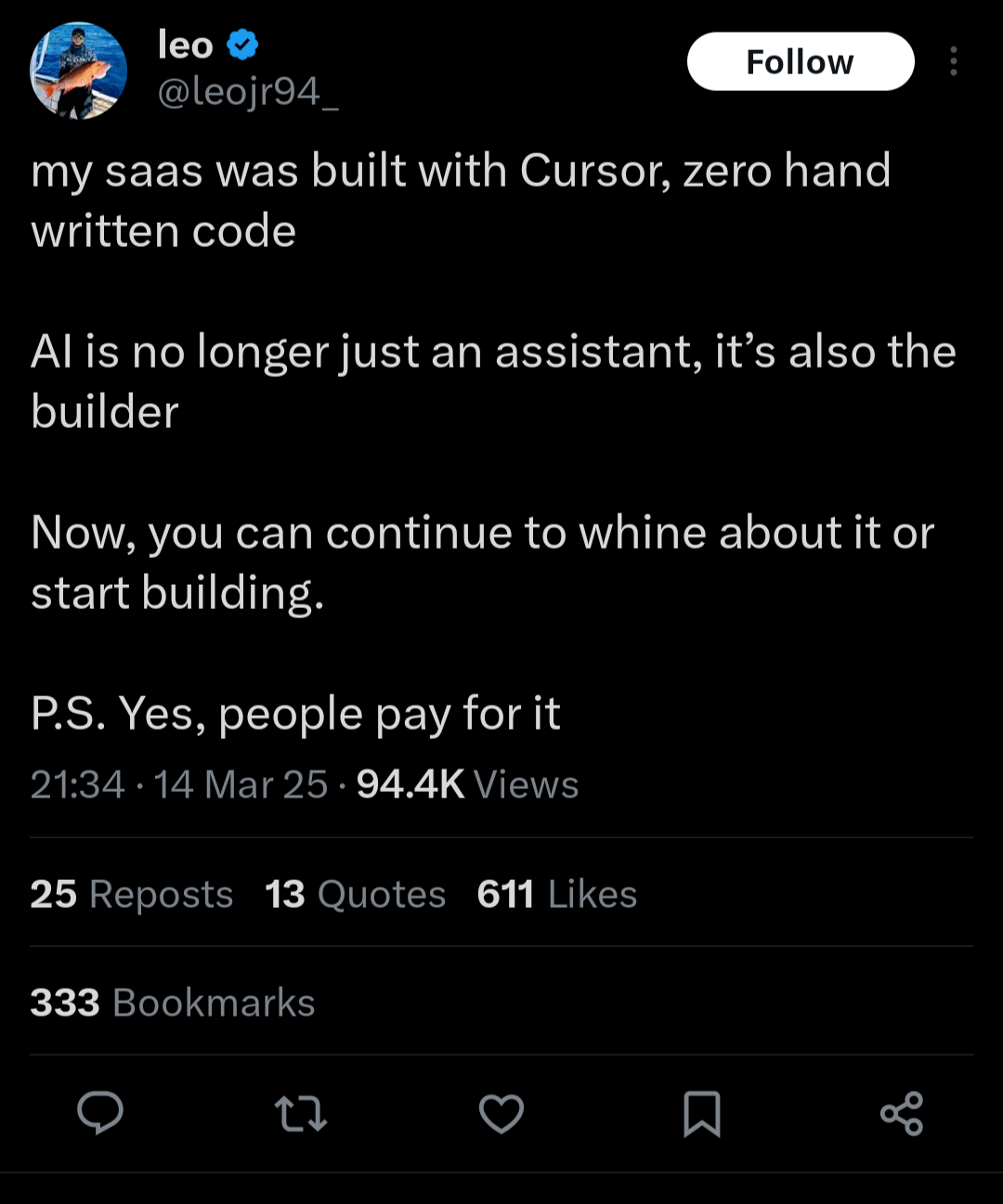
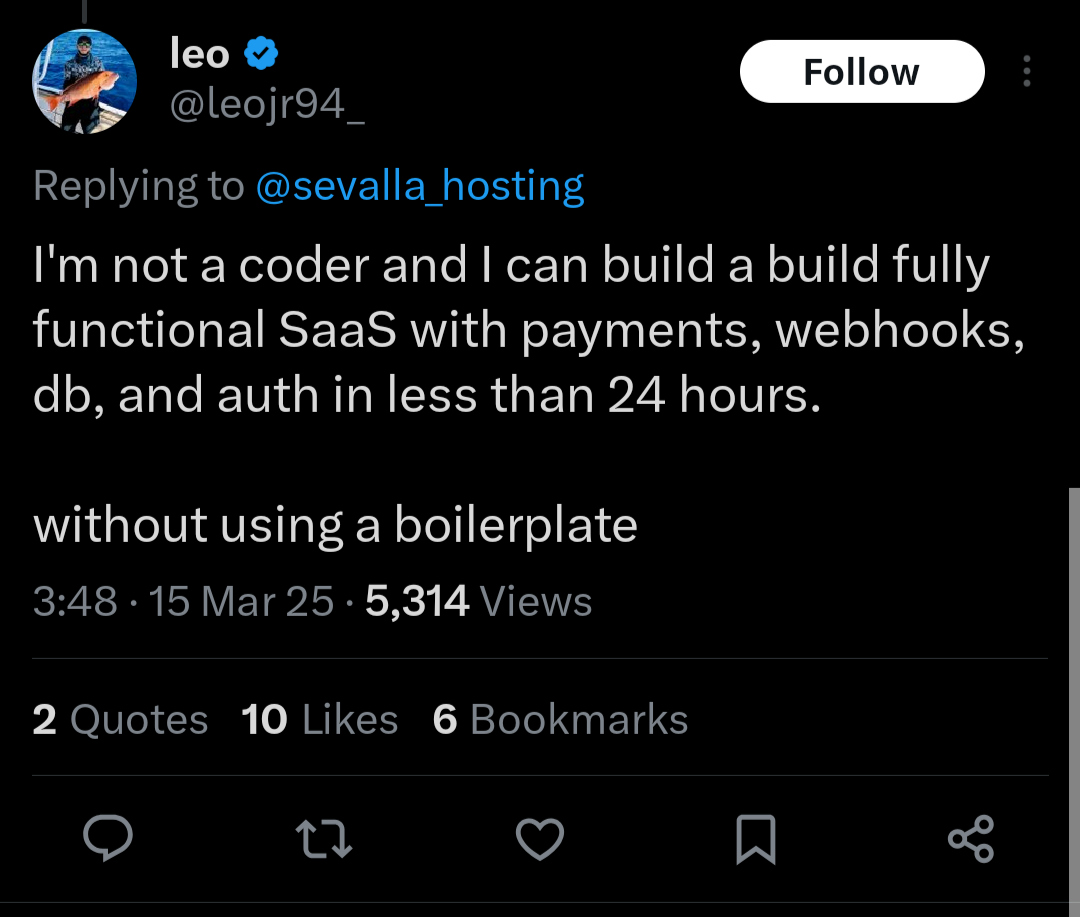
And it ends with this series of tweets, which I will call "Me Reaping":
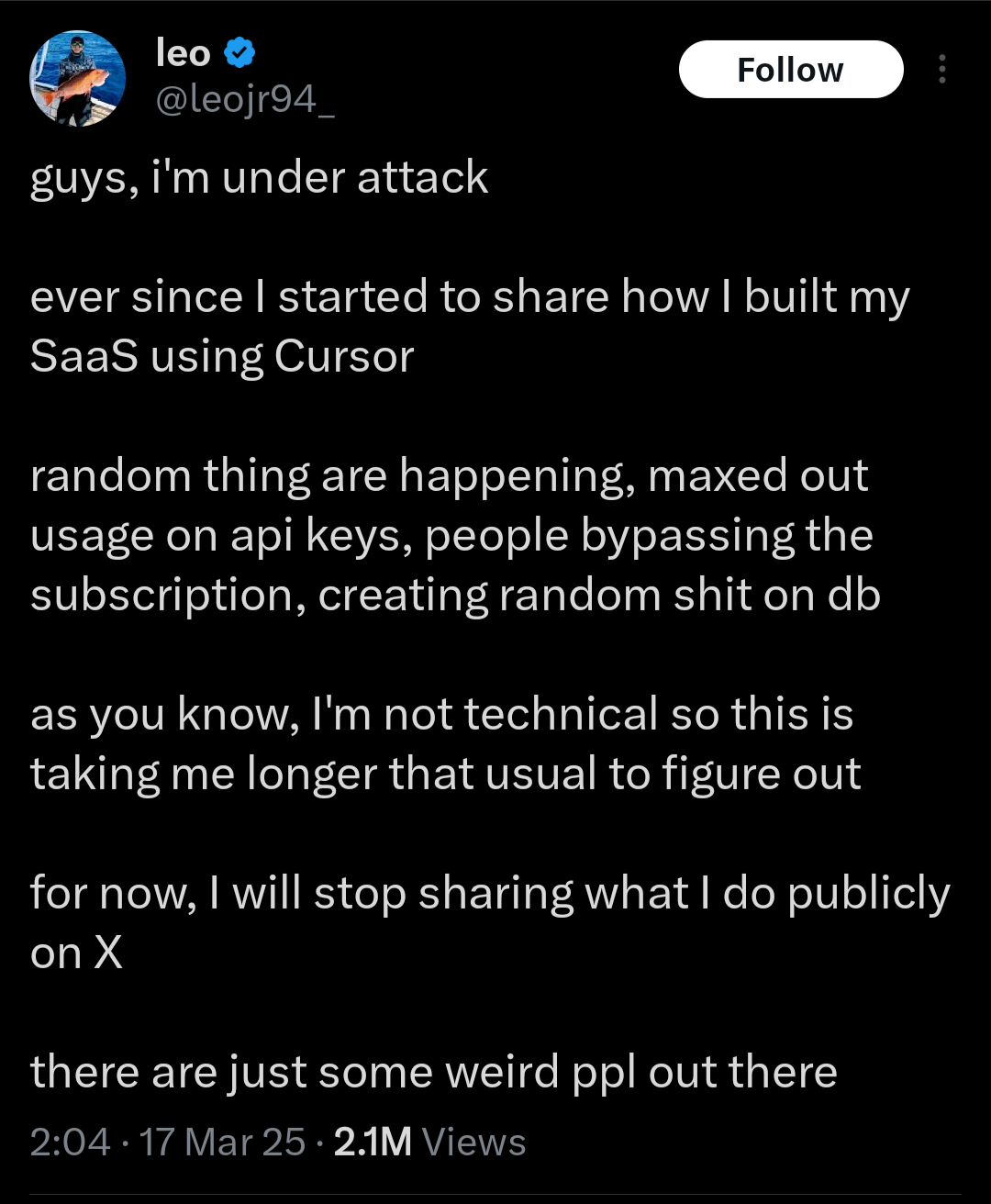
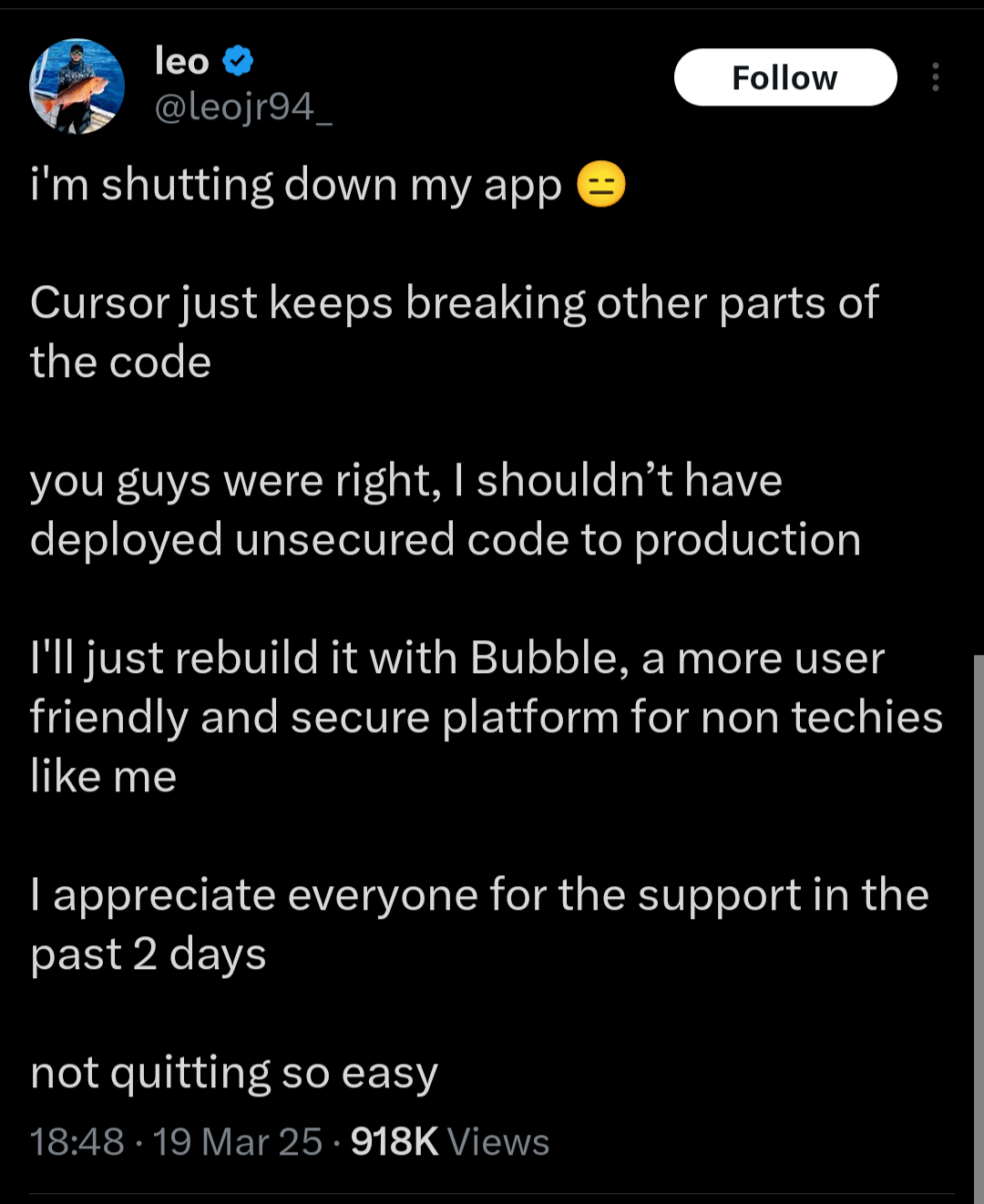
Now, it's funny to laugh, but of course this is what a tool like this is purposed to immediately.
In our current social and economic environment, every incentive is towards someone doing exactly this and not thinking too hard about any of the risks.
In many ways, that is the start up model.
In any case, it is clear that people are and will be inclined to use these tools this way.
Worse still, I think there may not be any really good use case for them, as currently articulated, at all.
The Dilemma
I think fundamentally tools like this face a dilemma.
Namely, if you know what you are doing, they are not that useful and in fact might turn simple problems into harder ones when it matters.
On the other hand, if you do not know what you are doing, then they create too much social risk to be countenanced.
Useless if You Know
There is a commonly accepted sentiment now that reading code is harder than writing it3.
Now, consider what the actual experience of "vibe coding" is in the long term for an engineer.
In the initial phases, where all the work is easy and could be done by rote, the work is still easy. It's certainly faster and requires less cognitive effort.
However, there comes a point where the work scales beyond the abilities of the autonomous drafting capabilities. As the original post itself noted, eventually the system cannot autonomously resolve bugs observed by the user.
Now our engineer is in the place of having to either randomly attempt to get the LLM to make changes, which may make an indeterminate amount of time and be more difficult than actually fixing the bug, or go fix the bug directly themselves.
Presumably, a usual engineer just rolls up their sleeves and tries to go fix the bug directly.
But they have a problem! They've had a lot of code drafted for them, and as such they have no mental model of the function of this code and its components or its dataflow.
All that cognitive effort they avoided in drafting the boilerplate or initial set up and first few features is now incurred all at once.
Worse still, it is no longer the cognitive effort required to write the code, it's the cognitive effort to internalize the entirety of the codebase by reading the code.
As we observed above, that's strictly more effort because reading code is harder than writing it.
So we've traded a tedious and simple problem whose total effort is amortized over time for a difficult problem that must be solved all at once4.
This doesn't look like much of a win to me, if it is true that we'll hit this scale limit for anything of non-trivial complexity.
Harmful if You Don't
Now, if you don't know what you're doing, then this tooling I think is the opposite of helpful.
As we saw in the case study above, it encourages a kind of over-confidence that leads to dangerously incomplete software.
I don't think this is a necessity, surely someone careful and unusually curious could avoid such downfalls, but I do think the dynamics of the tools incline towards this outcome.
Since the tooling abstracts over the code produced unless you elect to inspect it, for the uninitiated this looks like totally transparent execution of their request. They are in no way prompted to look at what is being achieved on their behalf.
As such, they can't be put in the position of asking in what ways what is produced might be lacking.
This leads to the sense that because what is produced is de minimis functional, it must therefore be complete.
However, this is clearly in no way true.
The tools have lowered the threshold of knowledge required to know enough to be dangerous. Everyone is now dangerous, left unsupervised.
And once a wall is hit, a bug emerges the LLM can't solve or a security vulnerability is exploited in the wild, the user of these tools is terribly unprepared to remediate the issue.
Low Confidence at Scale
Now, the dilemma above depends on the claim that the tooling will hit a point at which it becomes ineffective and it which "looking under the hood", as it were, becomes necessary.
Clearly, even practitioners of this technique recognize that this does happen, as we saw in the original tweet.
But I think there are even more fundamental reasons to think that these tools and techniques cannot scale to meet the challenges of everyday engineering.
The video above proving that Windsurf is effective, like many of these tools, makes a big show of autonomously generating the scaffolding and initial features of a project. I want to grant that this is genuinely pretty interesting and sort of impressive.
It is, however, I think a misdiagnosis of what the work of software engineering in fact is.
To that point, I think it's indicative to look at this image from Windsurf's website highlights this misunderstanding:
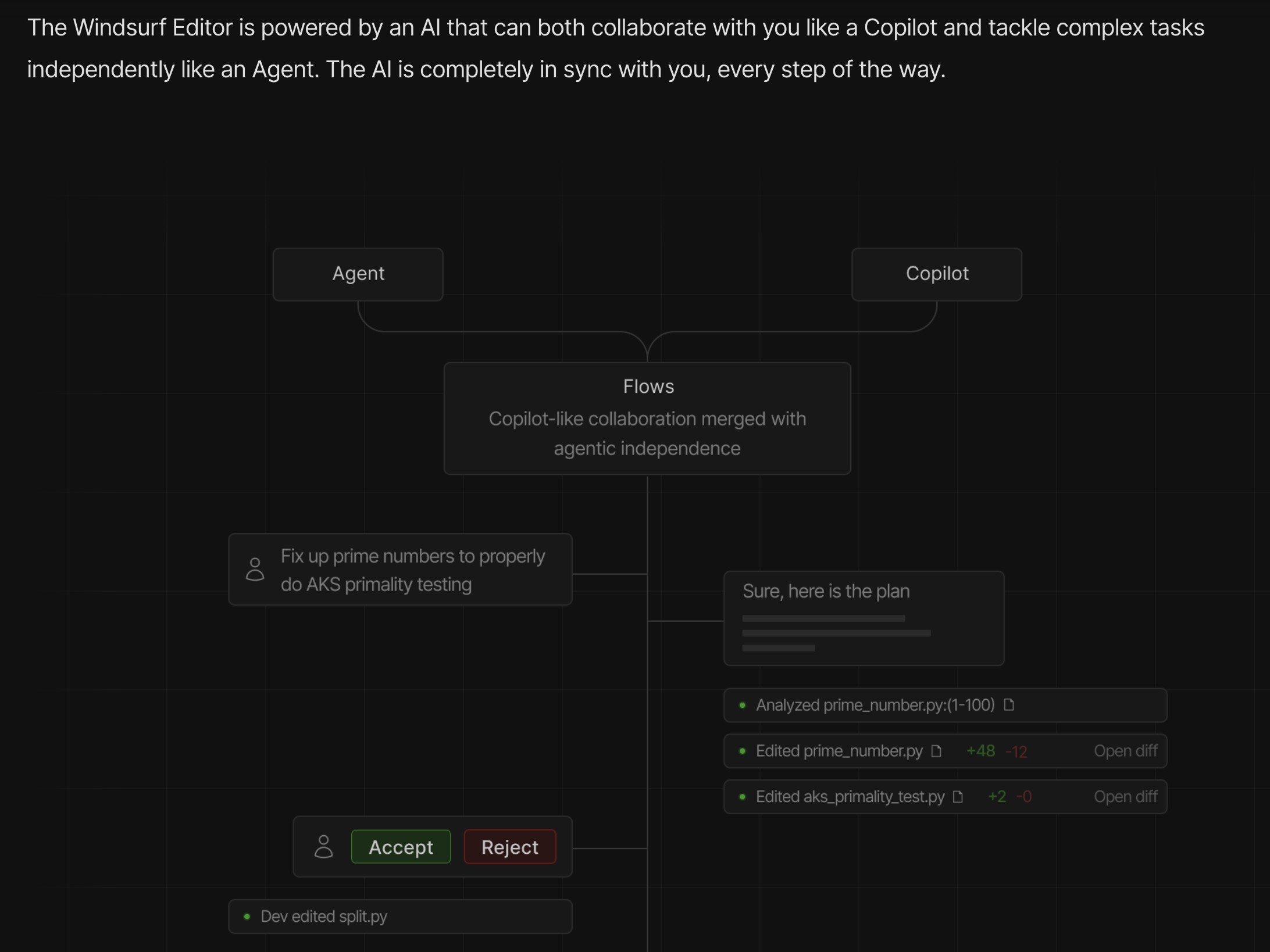
In this picture, they emphasize that Windsurf can solve "complex" problems, and the problem they choose is primality testing.
Now, procedurally, primality testing is a technical and relatively complicated piece of code5, the sort of thing you could expect someone with a technical degree in software or mathematics to solve, but would bounce someone with a non-traditional background.
It is not the kind of complexity that everyday software engineering actually involves, however.
The most complex and difficult problems in software engineering are rarely the kind of thing you can find an academic paper laying out an algorithm for (though certainly technical problems of that nature exist). They aren't even necessarily things with a single right answer (something notably the case in the primality testing example).
Far more often, the complexities emerge from long context, historical precedent, and mismatch between components due to accreted assumptions.
These are the exact sorts of problems that a human intelligence can navigate with aplomb, but that existing models cannot solve without grounding them on some artifact that evidences that context.
For example, it is easy to imagine a bug that, due to historical precedent and social context (maybe it's a regulatory requirement6), cannot be resolved in some specific way, but only in some other way.
A human can trivially ingest this context and use it to navigate the space of solutions that is admissible while excluding those that are not.
An LLM that has access to solely the textual contents of a codebase will lack that context, and not be able to solve it.
Even supposing the agent can condition on the Git history in a meaningful way (and with especially long and complicated histories this is not a given), there is no reason to believe that an LLM based IDE agent like this can obtain sufficient context to exclude the inadmissible solution.
This problem gets worse when the user is not themselves technically informed or educated - they may not even be able to detect the fact that the solution has been made in an inadmissible fashion.
In other words, this tooling appears to misdiagnose the fundamental sources of difficulty and complexity in software engineering, without remediating meaningfully many of the incidental sources of difficulty and complexity.
Pedagogical Tooling
I don't want to just be negative in this post though because I think accidentally these tools have hit on something true and genuinely interesting, and that's that a lot of people who cannot code really, really would like to, and that there is a real desire for environments that can help them learn towards building something real.
Interestingly, in both my own experience teaching myself to code and talking with other people who change careers into software I've observed a set of interrelated problems that people run up against as they learn that obstruct their ability to actualize their learning.
Many people make progress learning the basics of syntax, implementing procedures, and so forth, not least because many pedagogical materials focus on them.
There is a wall that people tend to hit where they want to parley those new skills into building something actual, but cannot actually manage to do so.
Figuring out how to use git, setting up the appropriate environment for a project, using the command line, understanding how to deploy some code somewhere, these are all fundamental skills that are less transparent and less easy to integrate against nascent conversancy in a programming language that one might want.
For another thing, though a person starts to learn how to write a solution for a problem, the question generally remains open on what the most idiomatic or best way to write it is, and it can be difficult in an auto-didactic setting to get some vision into that. It doesn't help that many sites, like Codewars and so forth, have users that use every solution as an opportunity to code golf rather than produce the optimal balance of idiomaticity and performance.
It would be really interesting to consider repurposing some of these semantic indexing with an agentic IDE concepts towards something that was explicitly pedagogical in its orientation.
In order to do this, you would have to force much higher friction on the end user.
Any such IDE would have to push their user to look at the autogenerated code, maybe even asking them to explain it back to the IDE.
The IDE could prompt the user to complete some portions, and even give feedback on the idiomaticity or suitability of the user's provided solution.
Something like this can never replace having a real human teacher, but I think there are really interesting ideas in this direction for a genuinely helpful environment for people to learn how to bridge their nascent programming skills towards building something more complete.
In Conclusion: The Dream of the Final Abstraction
In closing, I want to just observe that this whole thing, the idea that anyone can produce a total application with no formal training or investment in fundamental technical skills is a long tradition with dubious history of success.
Whether it's No Code, Visual Programming or the Logic Programming Paradigms of 5th Generation Computing Systems there is a history of attempts to solve the desire of non-technical persons to quickly implement functional software systems directly, without mediation by person's who have the required technical knowledge.
In a similar connection, SQL itself was originally designed to be easy enough to be used by business stakeholders directly7.
I think ultimately these attempts at total transparency and the elimination of computational and technical knowledge as a situated social function are doomed, and I think this latest episode reflects the perennial failures of this tradition.
I don't have much fear that something like this will replace software engineering as such.
More what I worry about is an acceleration of an already existing trend.
Every start up I've worked at has had an immense amount of technical debt that was produced in the first phase as they looked for product market fit8.
This technical debt was a millstone around the business that consumed absurd amount of technical resources to remediate. Solving the problems created by drafting quickly took often much more effort than correctly solving those same problems up front would have taken.
At least, though, in that situation, at least one person had genuine knowledge of the system as produced.
It is not impossible to imagine, if these tools continue on their current course, over-confident start up founders generating whole systems whom no one understands in any part, and only later attempting to remediate the fundamental issues with those systems as the business stabilizes and has actual social content.
At least with the existing model, a few junior engineers might get their foot in the door writing all of that doomed code.
That model is certainly bad, and a foolish deployment of human time and intelligence, but it's got to be better than a totally autonomous version of the same.
Though I do think such tools do require care and attention to be used appropriately in some domains, for reasons similar to those discussed in this post.
Or, at least, this is the pitch.
Specifically, Windsurf's Cascade offering.
Here are two canonical citations for this idea (the first a quarter of a century old!):
But there are tons of posts and talks about this fundamental assymmetry in the work of software engineering.
A lot of what's happening here is that the knowledge that is byproduct of coding is an essential component of the process of producing sustainably working software. In many ways, this is similar to the argument advanced in information literacy research relative to this paper: The Perfect Search Engine Is Not Enough. The procedures used in searching are integral part of building sufficient context to correctly interpret the final result. The final result is not useful without that context. A seeming inefficiency turns out to be load bearing.
Though, I would argue it is one of those "once you know the trick" easy enough things that so many people overindex on in the subculture that over-valorizes software engineering as a technical discipline.
A real thing that has happened to me, for example.
And through its inarguable success, causing decades of engineers to build libraries bridging the mismatch with the semantics of their own programming languages. Looking at you ORMs.
Or whatever they were up to, I don't know, I wasn't there.